
告别“硬堆料”时代:摩尔线程全功能GPU的技术路线图与生态突围样本
在近日摩尔线程首届MUSA开发者大会(MDC 2025)的开场演讲中,摩尔线程创始人、董事长兼CEO张建中用这样一句话定义了过去几十年的GPU技术变革。这句话的潜台词是清晰的:在国产GPU赛道上,单纯比拼硬件参数的“硬堆料”时代正在过去,架构的通用性与软件生态的成熟度,正成为衡量技术护城河的新标尺。
从地下的盾构机大脑到指尖的眼科手术机器人,从气象大模型的云端推演到挖掘机的边缘计算,大会现场覆盖AI大模型&Agent、具身智能、科学计算、空间智能等前沿技术领域,延伸至工业智造、数字孪生、数字文娱、智慧医疗等领域的几十款创新应用,外加20+场专题论坛,将“软件生态”这个略显抽象的概念,具象化为可触摸的实体。

大会上,摩尔线程不仅展示了万卡集群的肌肉,更系统性地披露了其底层技术底座的演进逻辑——从MUSA架构的持续迭代到全新“花港”架构的亮相。这不仅是一次产品的更新,更是一次对国产GPU技术路线的“实地验证”:摩尔线程正试图通过架构层面的软硬协同,让国产算力从“可用”变为“好用的生产力”。
在摩尔线程的技术路线图中,“花港”被定义为新一代全功能GPU架构。与以往单纯追求制程红利不同,“花港”架构的核心突破在于通过微架构设计来“榨取”性能。
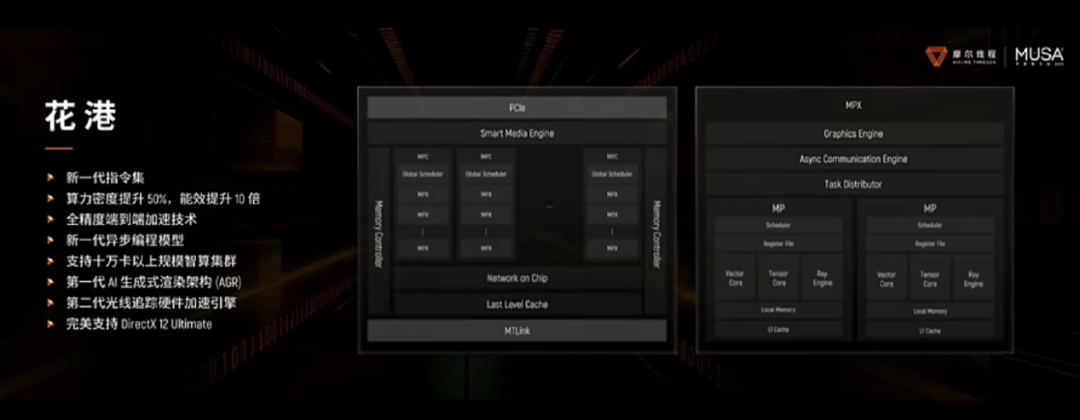
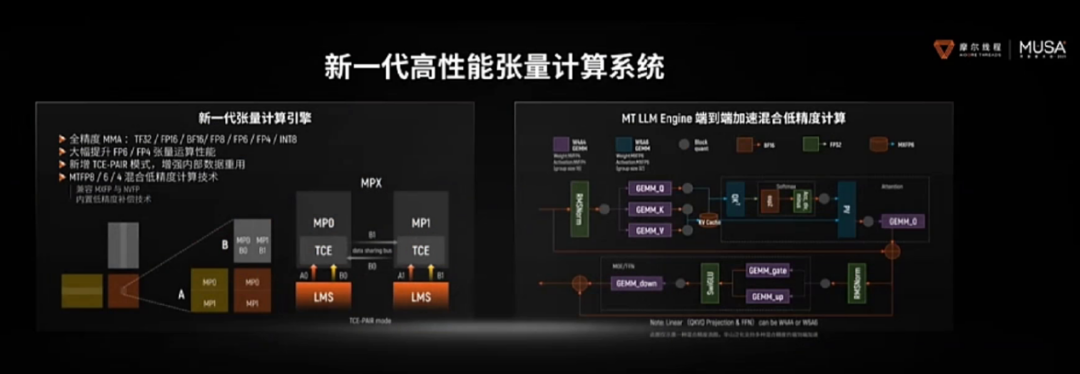
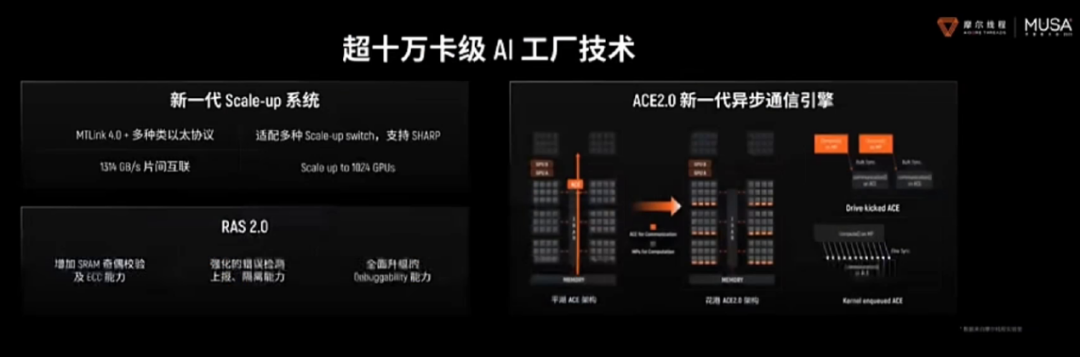
架构的先进性最终需要通过集群来验证。基于“华山”的前序技术积累,摩尔线程发布的夸娥(KUAE)万卡智算集群已经交出了工程化的答卷:在Dense大模型上MFU(模型算力利用率)达到60%,训练线性扩展效率达95%。特别是在DeepSeek V3模型的复现中,摩尔线程通过自研FP8 GEMM的精细化优化,不仅突破了FP8累加精度的瓶颈,更实现了算力利用率高达90%的成绩。这证明了其架构在大规模工程实践中的可靠性。
MUSA 5.0软件栈:生态是核心护城河
“生态体系是GPU行业的核心护城河与价值所在。”张建中在大会上强调,摩尔线程致力于攻克从硬件到软件的核心技术挑战,目的就是“共同构建自立自强的国产计算产业生态”。
性能优化方面,为了解决兼容带来的性能折损,MUSA 5.0在底层计算库上进行了极致优化。数据显示,其核心计算库muDNN在HGEMM和FlashAttention等关键算子上的效率超过98%,通信效率达到97%。
在大模型推理端,摩尔线程与硅基流动的合作就是一个典型样本。通过深度适配MUSA软件栈,双方在DeepSeek R1 671B全量模型上实现了性能突破:S5000单卡Prefill吞吐突破4000 tokens/s,Decode吞吐突破1000 tokens/s。这一数据不仅树立了国产推理性能的新标杆,也验证了MUSA软件栈在处理复杂大模型时的从容。

而随着AI计算的个人化,摩尔线程也在企业级市场之外完成了个人智算平台的关键拼图——MTT AIBOOK。与传统笔记本电脑不同,MTT AIBOOK针对开发者群体,在50TOPS异构算力基础上提供了开源计算加速库、通信库等核心组件的底层支撑,预置了VS Code、PyTorch、vLLM等全套开发环境,支持Linux/Windows/Android多环境切换,实现了AI学习与开发的开箱即用。配合摩尔学院20万开发者学习资源,AIBOOK或许可成为个人开发者接入国产AI生态的“入口级”载体。

谈及未来规划时,张建中表示,摩尔线程将在明年上半年开放中间语言MTX 1.0,并逐步开源计算加速库(MATE)、通信库(MT DeepEP)及系统管理框架。前者类似于CUDA的PTX,允许高阶开发者绕过上层封装,直接对GPU硬件资源进行细粒度的调度和优化,后者则有助于构建一个更具活力的开发者社区,驱动生态体系从“可用”向“好用”进化。
全功能GPU的“物理AI”拼图
“庐山”芯片专注于高性能图形渲染,AI性能提升64倍,光线追踪性能提升50倍,并完整支持DirectX 12 Ultimate。这种设计思路试图利用AI算力来加速图形渲染流水线,从而实现从传统的“计算渲染”向“生成式渲染”的范式转变。这对于数字孪生、具身智能等“物理AI”场景至关重要。

张建中结束演讲的话语,既是对摩尔线程未来的期许,也是对中国计算产业的信心。MDC 2025展示的不仅仅是“花港”架构或MUSA 5.0软件栈的技术细节,更是一种构建自主计算生态的决心。在全功能GPU这条拥挤且艰难的赛道上,摩尔线程正试图通过架构的底层创新和软件生态的开放共建,为中国计算产业提供一个可行的、具备技术深度与演进潜力的替代方案。
扫一扫,关注我们